template for structuring data science notebooks
tl;dr: use this template when publishing your data analysis.

This post provides template (with example) for structuring ML/Data Science Jupyter notebooks and articles using CRISP-DM framework.
template
I always recommend CRISP-DM framework to beginners whenever they start new Machine Learning project for the following three reasons:
- Guides the efforts in a structured and effective way.
- Focuses on business impact as a main driver of ML project.
- Makes your work easier to follow, since it is well structured.
CRISP-DM stands for Cross-Industry Standard Process for Data Mining. It has six sequential steps:
- Business understanding:
- what problem we are solving?
- why it is important?
- what is considered as success?
- what metric will be used to measure success?
- Data understanding:
- does the data that we have match with our understanding of the business? If not, update your business understanding
- do we have sufficient amount of high quality data to formulate hypotheses?
- Data preparation: clean and prepare data for modeling
- Modeling: testing and training ML models, iteratively returning to step 3 (data prep) if necessary
- Evaluation
- What ML evaluation to choose given success metrics decided in step 1 (business understanding)
- Are we happy with predictive power of the model?
- If not, maybe we should revisit business understanding again
- Deployment
As we can see there is a lot of emphasis on the first two steps: business and data understanding. Unfortunately, many junior data scientists skip them and jump straight to coding part (data prep, modeling) and that would be huge mistake.
Business and data understanding helps in
- ideation for feature engineering
- selecting correct evaluation metric
- understanding biases in data
- understanding if it is worth doing at all
Remember that every company has a graveyard of ML models with amazing predictive power that were never deployed because they were solving wrong problem or had very little business value. Don't add another one there.
Therefore, my suggestion is to use this framework literally, which means that each step is one section of your Jupyter notebook. The same structure will work for an article based on this notebook, just drop few details and coding pieces whenever necessary.
example
The example I am taking to demonstrate the use of this template is the article I wrote when I was still doing my Masters in 2019.
In the Natural Language Processing (NLP) class, there was individual project assignment to detect Fake News. The small dataset of 4000 articles with labels Fake / Real was given. I combined classical ML and NLP methods to build a binary classification model and summarized my notebook in an article below.
Before we get to the project itself, I figured it is better to explain briefly some NLP concepts used in the project (feel free to skip next subsection).
relevant nlp concepts to know
Starting from the basics:
- Corpus: set of documents (our dataset of news with fake and real labels).
- Documents: basic unit or object (a particular news or tweet).
- Bag-of-Words (BoW) representation: representation of documents as a collection words with count value for each word. In this representation, what is important is how many times a particular word appears in the corpus and in each document, but not the order of words.
There are three main ways to calculate count value for each word in BoW representation:
- Binary weighting: the count value is binary indicator (does this word exist in this document?).
- Term Frequency (TF) weighting: the count value is just frequency of a word (how many times does this word appear in this document?).
- Term Frequency-Inverse Document Frequency (TF-IDF) weighting: in TF weighting the words like articles (the, a) appear a lot in each document, which bring little information to distinguish documents. We want rare words, because they are more informative that frequent ones (articles, pronouns, etc). We can solve this problem by taking into account the number of documents in which they appear. Therefore, the count value is real-valued number that is proportional to frequency of a word in this document and inversely proportionally to frequency of documents in which this word appears.
Terminology related to words:
- Stop-words: common words, that bear little value for differentiation, like articles and pronouns.
- Part-of-speech (POS) tagging: an identification of words as nouns, verbs, adjectives, adverbs, etc.
- Tokens and tokenization: separation of a sentence into words (tokens).
- Stems and stemming: crude chopping of affixes to base words (stems), so that several similar words convert to one. For example, "automate(s)", "automatic", "automation" all reduces to "automat".
- Lemma and lemmatization: reduction of inflections or variant forms to meaningful base form (lemma). For example, "are", "is", "am" become "be", while "cars" becomes "car". Lemmatization is more powerful than stemming, but also takes much more time.
- N-grams (unigrams, bigrams): contiguous sequence of N words. One word is unigram, two words are called bigram.
business (problem) understanding
Fake News Detection is quite popular problem nowadays (it was in 2019 when this article was written and still is). There is no doubt that it is very complex problem, because we see that even major platforms can't efficiently stop the spread of fake news, hiring many people, deploying sophisticated policies and models.
For example, some years ago old Twitter acquired startup Fabula AI, that has developed a technology to detect fake information using graph-based approach, analyzing the differences in the way fake and real information spread across the network. Another (simpler) approach would be to analyze the difference in the choice of words used in both fake and real news.
And this is what I did in this project.
Finally, the success metric is accuracy of classification. Finding real and fake news are equally important.
data understanding
The dataset contains 3999 news articles (title + text) collected from the web with labels either fake or real (around 50-50 split).
I had several hypotheses on how fake news might be different from real news:
- Talking about the same topic (i.e. politics), in fake news an author might use different words and n-grams (less formal).
- Fake news might be mostly about politics and crime, hence completely different words and n-grams are used.
- In fake news an author might use different POS tags, i.e. more adjectives and adverbs, like incredibly or breaking.
- Real news might be longer, because they tend to include supporting facts and references.
Summary of exploratory data analysis (EDA):
- By plotting average TF-IDF values for the top 50 words by each class (fake/real), there is slight difference between the words used, although the difference is not that clear for unigrams.
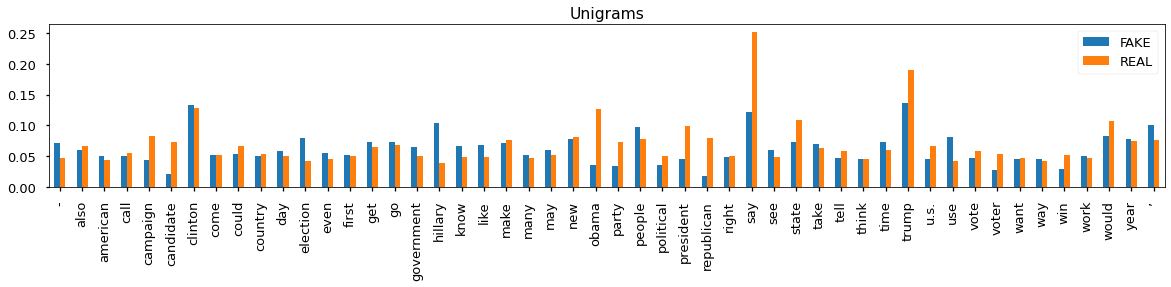
- This difference becomes clearer for bigrams.

- There is difference between fake and real news in terms of what POS-tags are used. Moreover, fake news seem to contain more SYM (symbols like $, %, §, ©, 😝), X (other like sfpksdpsxmsa), INTJ (interjection like psst, ouch, bravo, hello).
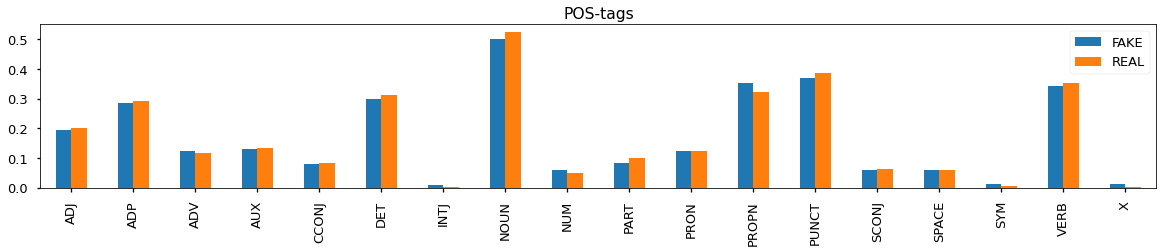
- Real news tend to have more tokens and characters
data preparation
I built two custom tokenizers using spaCy library and their medium-size pre-trained statistical models for English (trained on web-content such as blogs, news, comments):
- To get lemmas of tokens, which are not corresponding to POS tags SPACE, PUNCT (punctuation: .,:?), X (other: xasdasdg), NUM (numeral: 1, 2017, one, IV), SYM (symbol: $,§,©,,−,÷,=,😝), DET (determiner: a, an, the), PART (particle: 's, not).
- To get only POS tags
Since one of the hypotheses was that fake and real news use different words, it is important to remove stop-words to better see the difference.
modeling
The approach for the modeling was the following:
- Start with creating a classification model using only TF-IDF values of unigrams.
- Create a model using bigrams.
- Combine unigrams and bigrams to see if the model improves.
- Build a model using only POS-tags.
- Combine POS-tags and the unigrams/bigrams to see if the model improves.
The above procedure was repeated for each of the following Machine Learning algorithms from scikit-learn:
- Linear classifiers with SGD training.
- Naive Bayes classifier for multinomial models
- Linear Support Vector Classification.
evaluation
For every model:
- Unigrams + Bigrams are better than just Unigrams.
- Unigrams + Bigrams + POS-tags are better than Unigrams + Bigrams.
After optimizing all models, I combined all three using Voting Classifier and it gave slightly better results than each individually.
deployment
I prepared for deployment by grouping the code into one class:
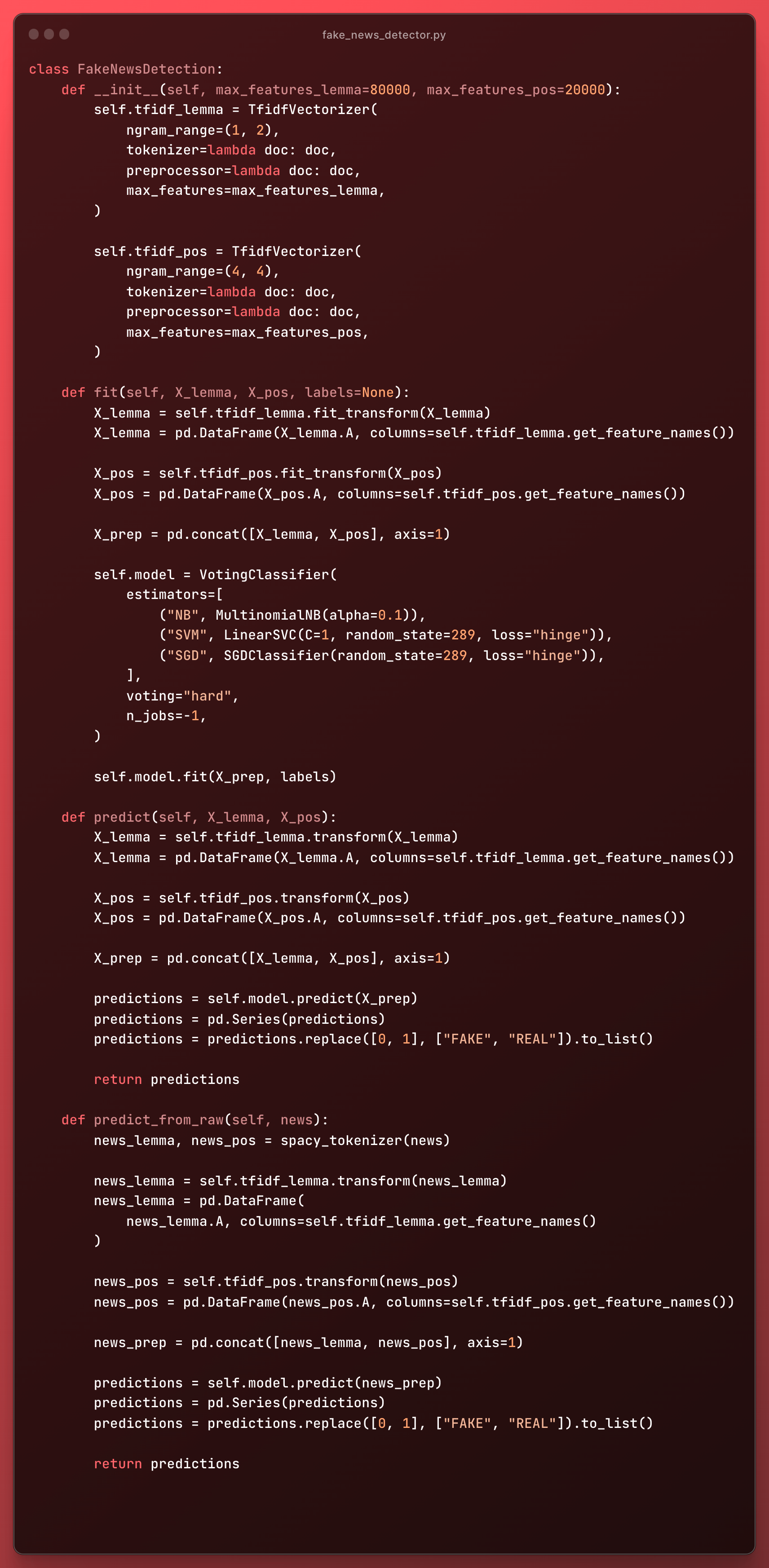
The Jupyter Notebook with the dataset, code, and full description on my GitHub:
 adgapar
adgaparNext time you do ML project, I encourage you to give CRISP-DM a try!



