how i teach python for data science

intro
In this blog post I share my syllabus for teaching introductory Python for aspiring data scientists.
Python is one of the most widely used programming languages and is one of the key languages in working with data, so no introduction is required from my side. However, since many engineers use it for web development, there are naturally different ways to learn it depending on if you want to build web apps or ML pipelines.
My syllabus summarizes what I consider the essential 80/20 of Python for Data Science. I split it in 7 lessons (2 hours each), after which students can start learning applied Machine Learning.
Here is the summary and key points:
- First two lessons are about basic Python.
- Time complexity is introduced in lesson #1 by measuring execution time. Same way as in experimental physics: you measure an event in a lab, then eventually develop (or learn) theory to explain the measures.
- Testing is introduced much earlier, in lesson #2, by showing how to use
assert. It is important to start developing a good habit of thinking about tests and writing testable pieces of code early on in career. - Similarly to testing, it helps if students develop a habit of writing comments, type hints, and docstring early on and that's why these concepts are covered in lesson #2 as well, together with functions.
- Lessons #3 is numpy
- Lessons #4 and #5 are pandas.
- Chaining is preferred way to write code in pandas. The code is cleaner and it enforces pipeline thinking that will help in the future in creating data pipelines, deploying ML models, and using new libraries such as polars.
- Loops were covered in lesson #2, but should be forgotten in data since we can't iterate over each row in a big dataset. In lesson #5 I explain how to write performant pandas code
- Lesson #6 is data visualization
- Lesson #7 covers intermediate/advanced topics in Python such as decorators, generators, OOP
pre-class: reading assignment
Before even the first lesson, I like to share this thread on YC Hacker News:


I love it, because it sends correct message to the beginners who decided to learn Python and then immediately felt confused, powerless, and drown by enormous amount of information on how to correctly install it. I, as many other engineers who posted in the news thread, am confused too.
It is not your fault, it is Python's - that's the message.
lesson #1: intro to python (1/2)
I start the first class by discussing the article above.
I nudge students to start with conda (Anaconda Navigator / Google Colab), but still give them the context on what is virtual environments, why they are important, what is versioning (semantic versioning X.X.X) and the role of packages and dependencies. I personally use Visual Studio Code to run Jupyter notebooks, but it often confuses students and therefore let's just use Anaconda / Colab.
Once the big picture is displayed, I move to details.
types and data structures
I start with data types and built-in data structures. To show the difference between data structures I introduce two important concepts straight away:
- mutability
- time complexity
I don't like overloading students with too much theory at the beginning, so time complexity is shown simply empirically by measuring the execution time of a operation with %timeit, %%timeit.
If there is extra time left, it could be beneficial to show data structures from collections, mainly defaultdict and namedtuple, but completely optional.
example on how i use %timeit
Checking if an element exists in a list shows different execution time. This operation is O(n) since we go through each element one by one. Since element 100 is not in a list, it will go through the entire list from start to finish and the execution time (as expected) is roughly double of the time when the desired element is in the middle of the list.
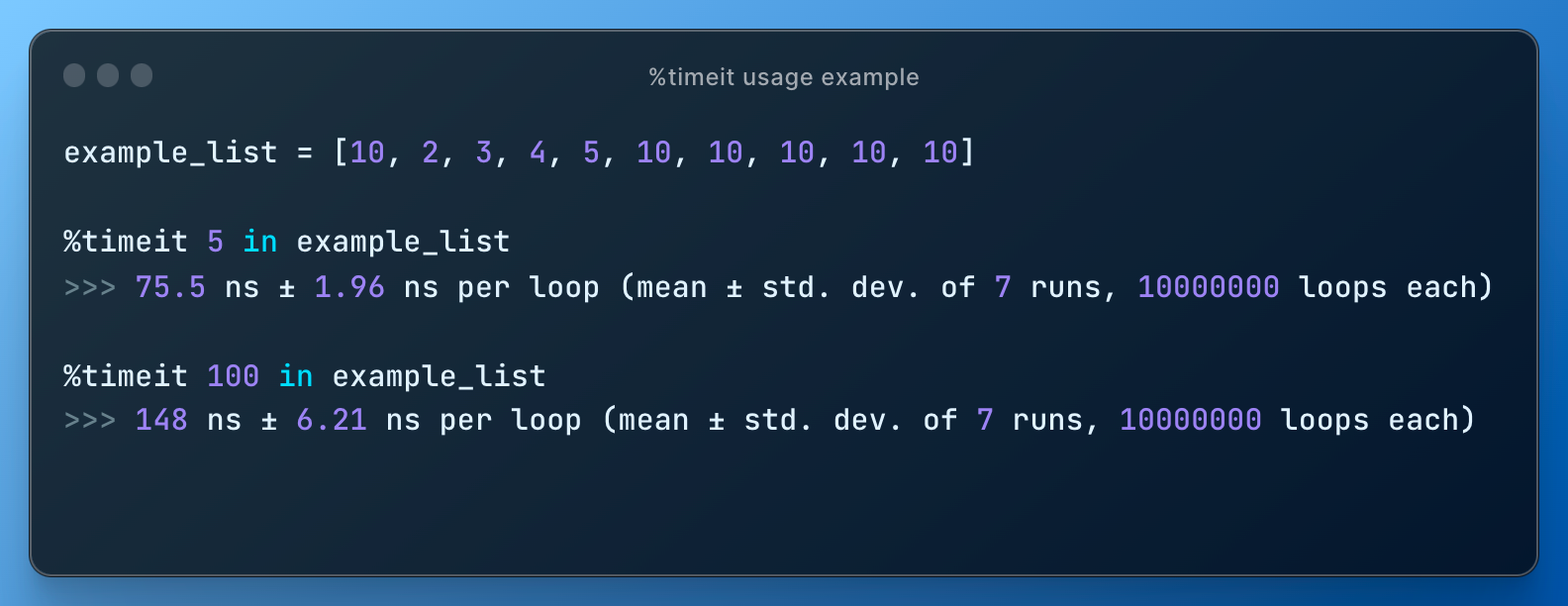
Checking existence in a set portrays different picture:
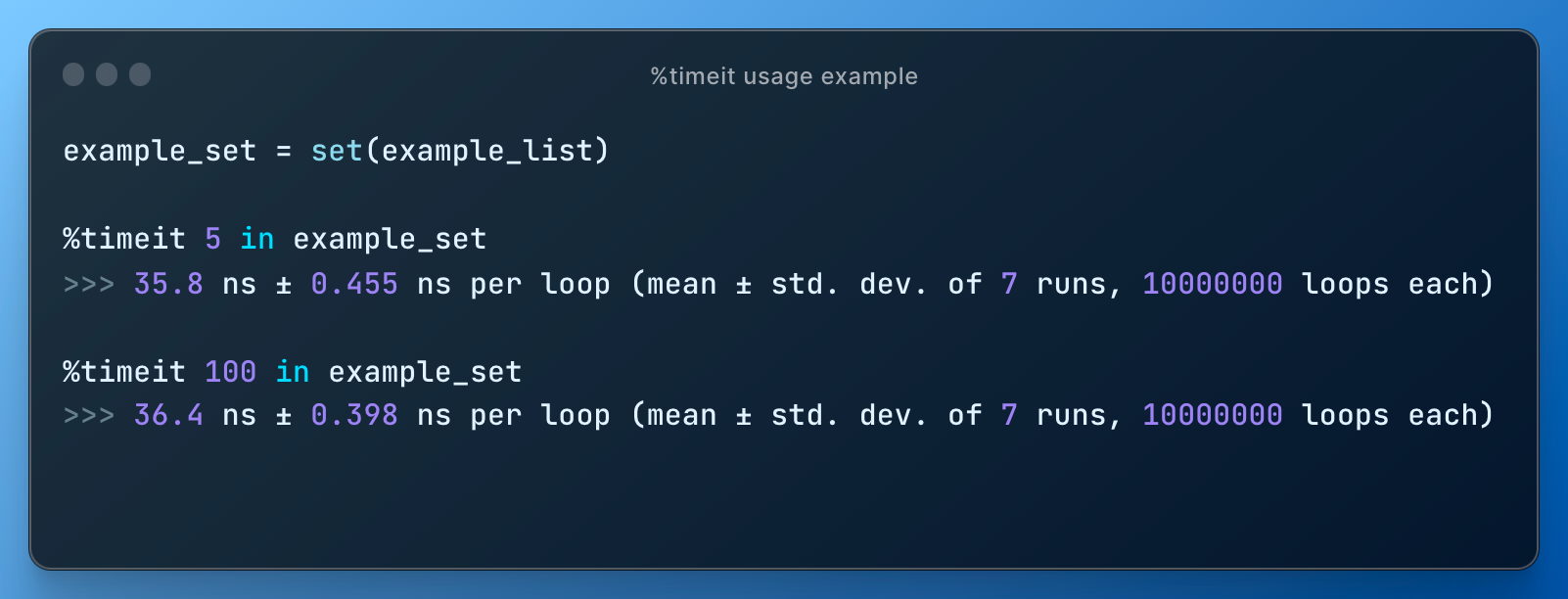
Such demonstrations aimed at triggering curiosity among students and promoting intuitive understanding that a choice of a data structure should be driven by use case and has clear consequences on performance of an operation.
control flow
Finally, the first lesson ends with control flow (if-elif-else, not, ==, >,<, truth-y/fals-y) which is easy to understand and doesn't take more than 5 minutes.
lesson #2: intro to python (2/2)
The second class is all about loops, functions, and error handling.
repetitions
I use this (simple) problem #1 from the Project Euler website.

The sum of these multiples is 3 + 5 + 6 + 9 = 23
Find the sum of all the multiples of 3 or 5 below 1000.
I solve this easy problem using for-loop/while and in the process we cover range, continue/break and list comprehension and dict comprehension.
The straightforward baseline approach (more efficient will be later) to solve it is:
- list all numbers < N
- check if number is divisible by 3 or 5
- if yes in step 2, save it.
functions
In the problem above they are asking for numbers below 1000. What if we need numbers up to 10,000 or 2,000 or 500? That's fine, let's just define new function that will contain our written loop code and add an argument.
So we go from this
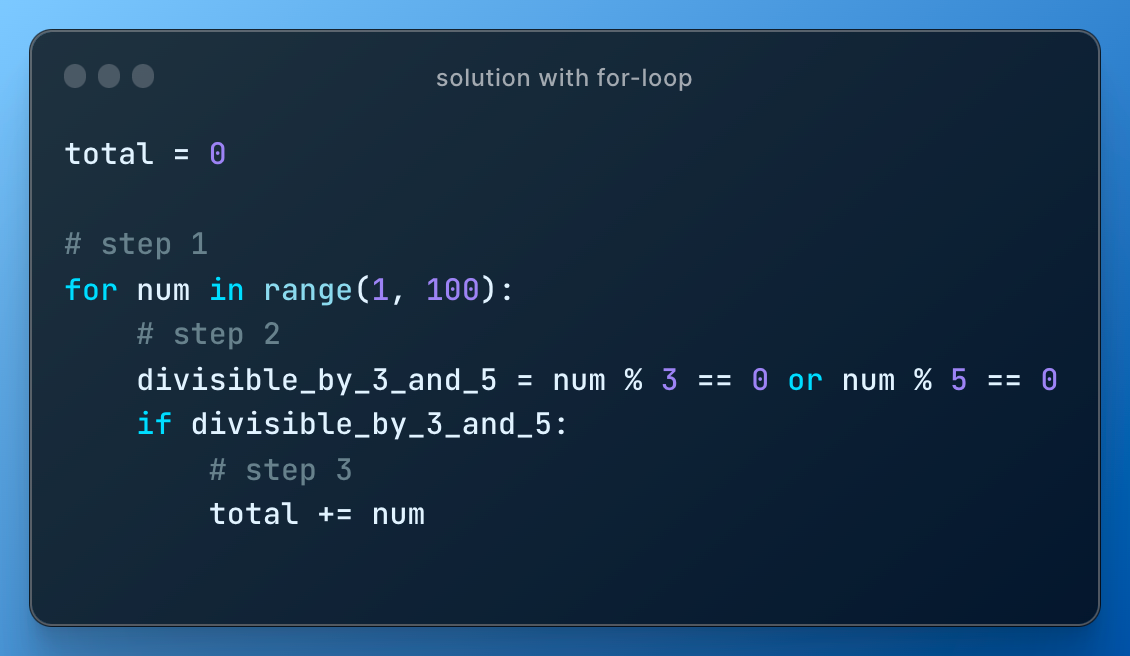
to this
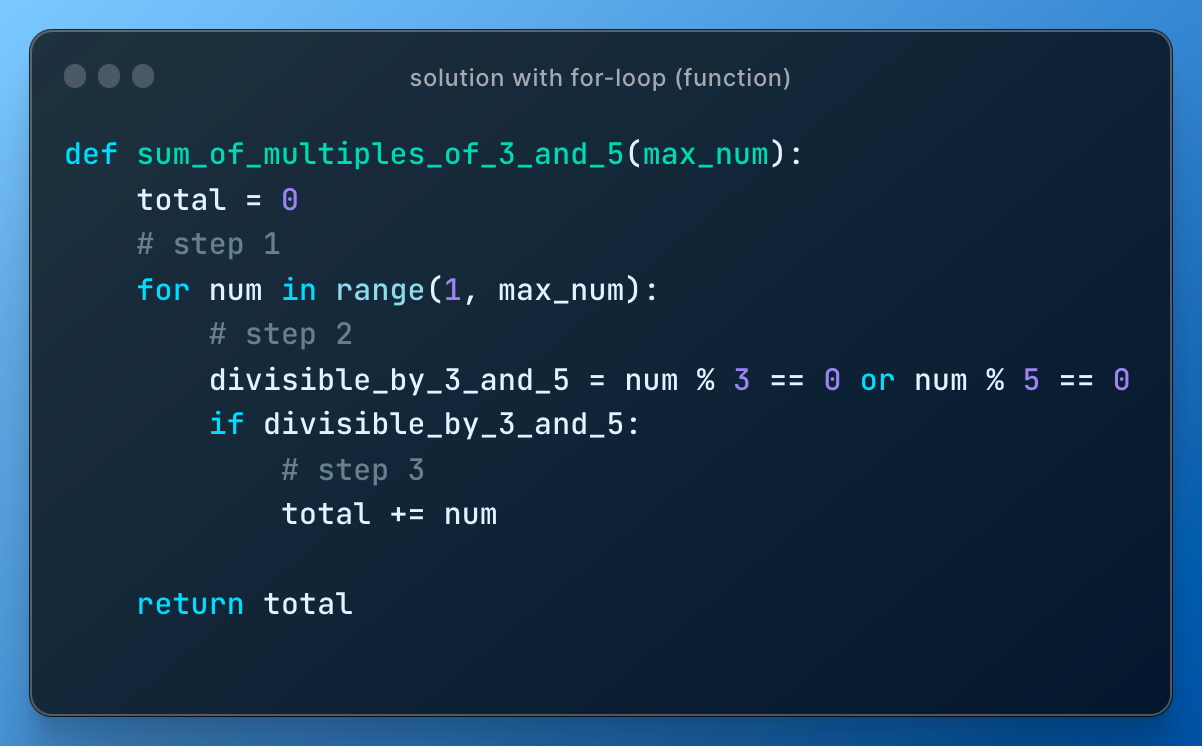
or to this to show that one function can use another function
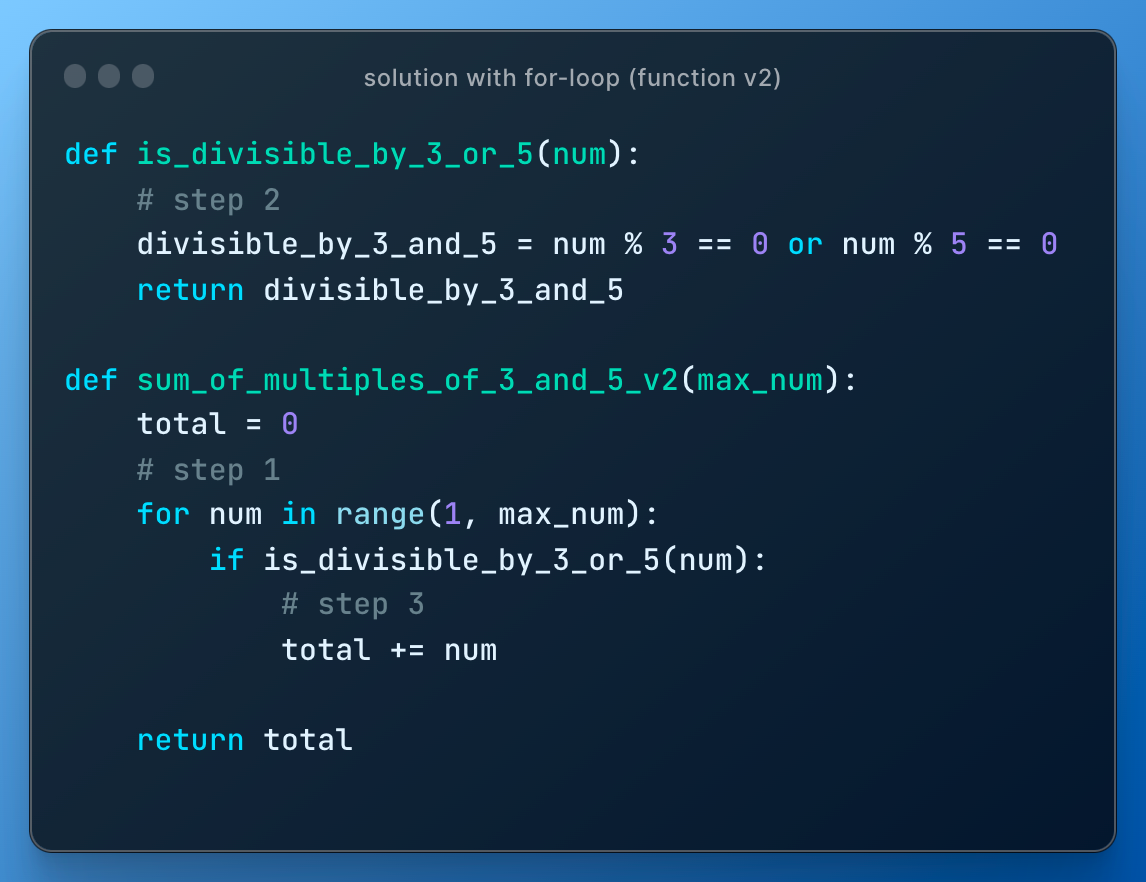
Time complexity: I run %%timeit with different max_num and everyone sees that execution time grows linearly with max_num due to looping through each element one by one.
testing
Testing is something many junior engineers ignore and as they gain experience they start focus more on it. I believe it is because testing is not prioritized properly during education period and I think it is wrong. It is a habit that should be taught from the beginning.
Right in the second lesson after writing the function, I just type the following:
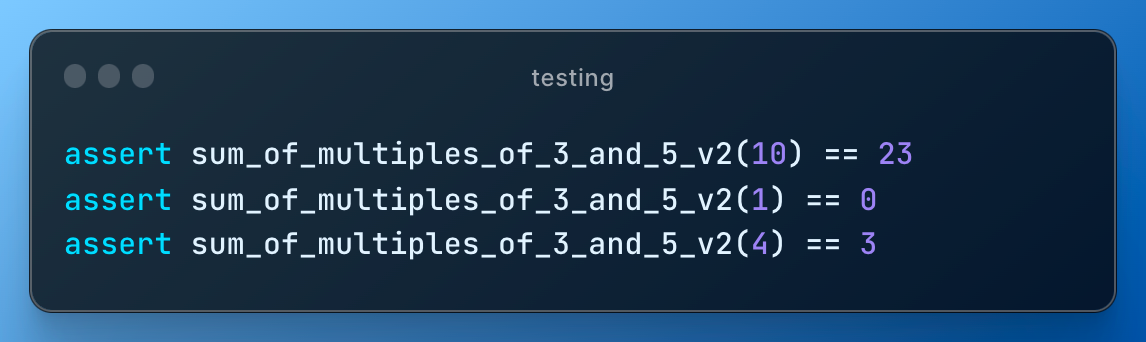
From the problem statement we know that sum of multiples below 10 is 23. Perfect, one test case given to us for free and I add few more that are easy to calculate manually.
There are libraries to run automated tests, but it is not a point here, so need to explain or even mention pytest. The point is developing a habit of always writing "tests", even if it means just few assert statements.
refactoring
After we have a function and simple tests, I ask students if we can do better, meaning can we reduce execution time of our solution?
I want students to think of this problem not as a programming problem, but mathematical - what if they have just pen and paper? In other words, I force them to think of an algorithm and not rely on computational power. Engineering and data science is a bit more than just writing code.
This specific problem of finding sum of all multiples of 3 and 5 below N can be resolved mathematically in the following way:
- sum all multiples of 3 below N
- sum all multiples of 5 below N
- deduct multiples of 15 below N, since these numbers were counted twice in step 1 and 2
3 + 6 + 9 + 12 + 15 + ... + K = 3 * (1 + 2 + 3 + 4 + 5 + ... + n)
where K = 3*n and K <= N.
Numbers from 1 to n is simply arithmetic progression and its summation is equal to n*(n+1)/2, which makes the final answer to be
3 * n * (n + 1) /2, where n = N // 3
The formula above is applicable to 3, 5, 15. The resulting solution can be coded as
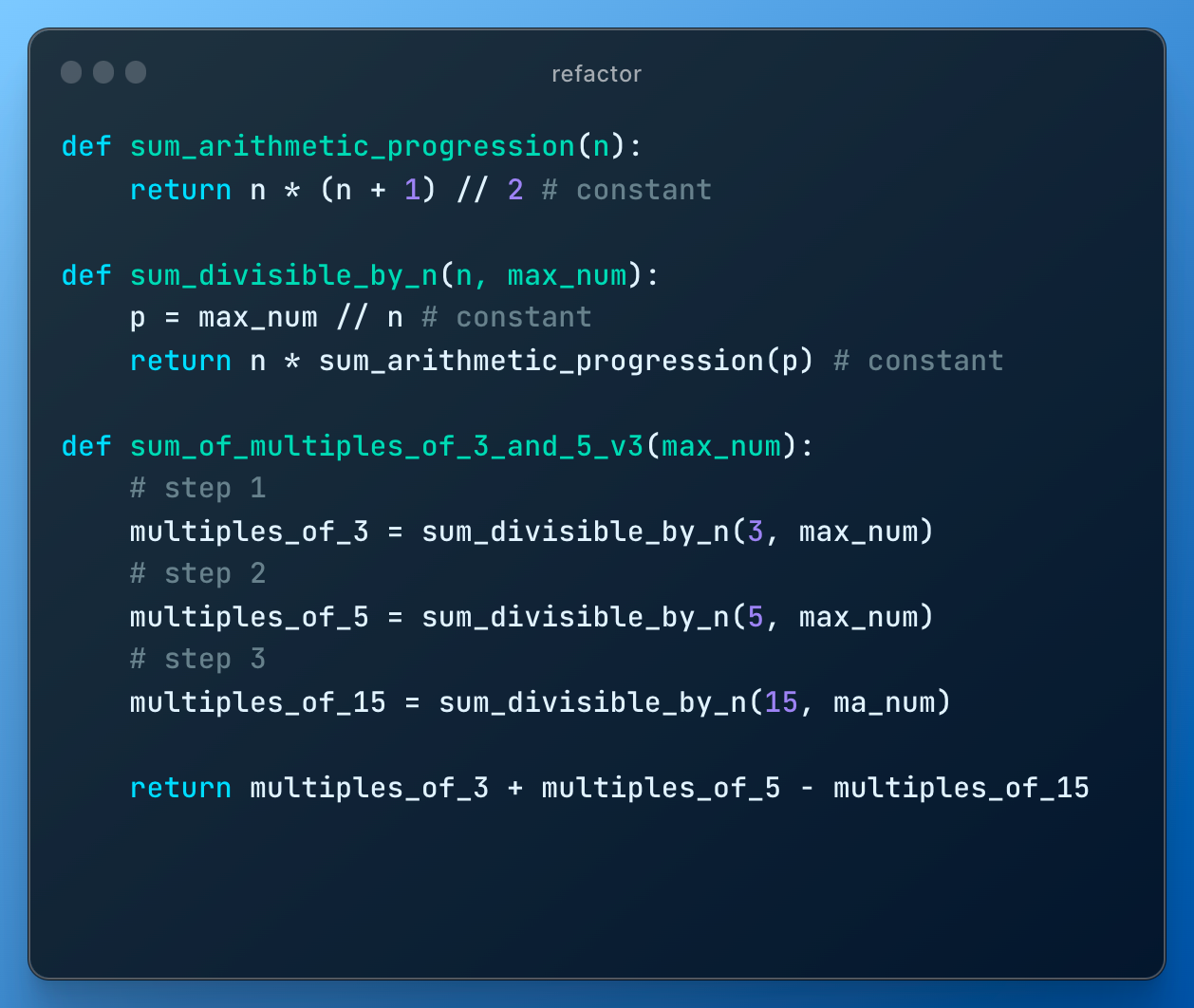
I run different max_num and students see that the time is constant.
proper style: type hints and docstring
There is no reason why it is a bad idea for beginners to know what are the type hints and docstring. On the contrary, they are easy to write and understand and, similarly to testing, enforce good habits from early on in career.
error handling
I don't spend too much time on errors, but if I have time at the end of lesson #2 I briefly show try-except-finally.
lesson #3: numpy
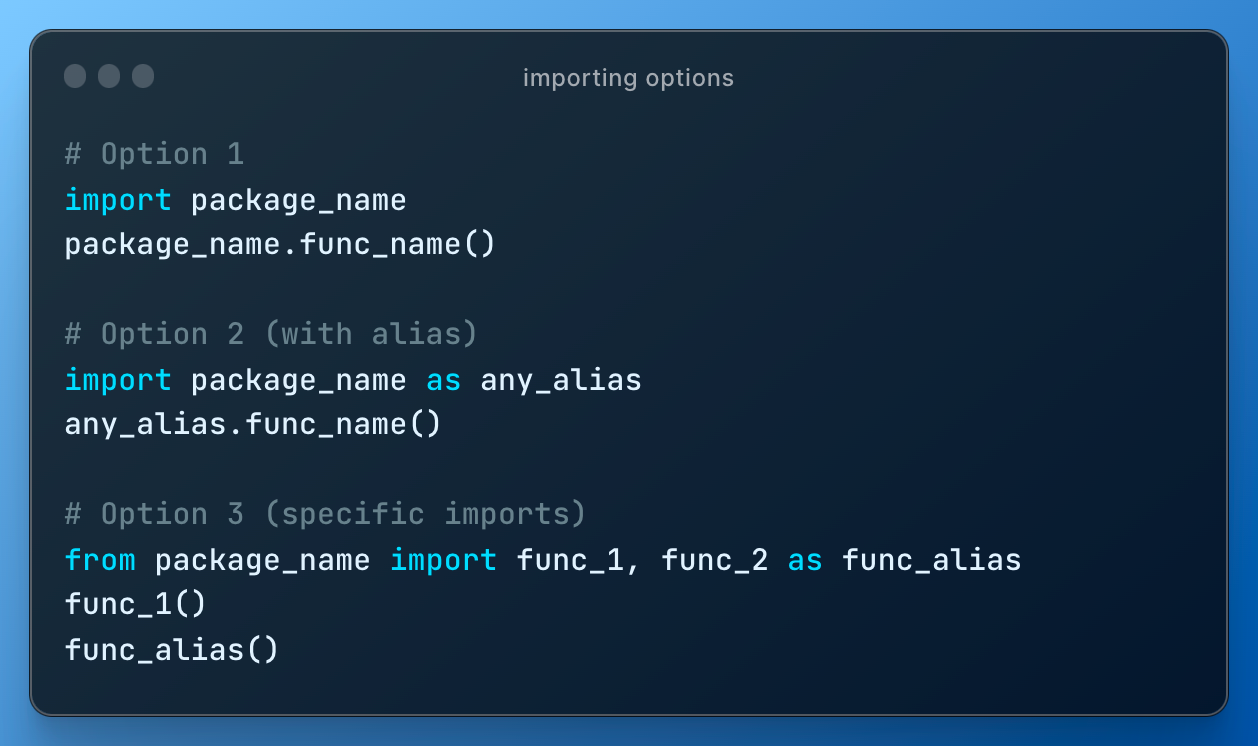
After we covered basic Python, we start specializing in data science related libraries. It could be the first library that students imported so far, so sometimes it makes sense to show how to import libraries:
First and foundational among them is of course numpy. No special treatment, just showing new data structure np.ndarray and numpy methods. I like showing the difference with matrices implemented as list of lists.
lesson #4: pandas (1/2)
Natural move from numpy to pandas, ndarray to DataFrame/Series.
create df
I start by demonstrating how to pull data from different sources, not only CSV as many typically do. Most of the bootcamp students interact with Excel on a regular basis at current jobs, so it is important to show how to get data from Excel. I also briefly show how to read from databases (PostgreSQL, BigQuery) just so that they know the differences and similarities.
I also show to create DataFrame from scratch.
manipulate df
Once the DataFrame is created, I just go through different operations that you can do to explore it: various basic methods, filtering, selection, basic aggregations.
lesson #5: pandas (2/2)
It is the last official lesson dedicated to pandas, but in the future once students start to do feature engineering, there will be more tricks explained.
apply
Students should know how to write functions by now. Now we need to teach how to apply these functions to the dataset. Hence, important topic to cover is .apply() method.
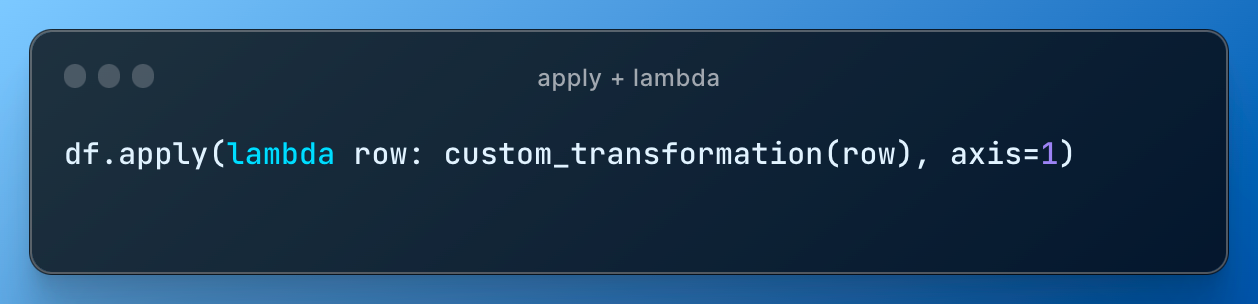
lambda
I also show how to write nameless functions aka lambda functions, since this is where they are mostly used in data science:
replace
During preprocessing of a dataset to be used by ML model we often need to encode categorical values (strings), which basically means replacing strings by numbers. It is true that you can do so with standard LabelEncoder() and OneHotEncoder() or with my favorite TargetEncoder() from category_encoders library. However, I find it is sometimes much easier and logical to just do custom replacement with .replace().
merge
Different ways how to join DataFrames. Easy.
chaining
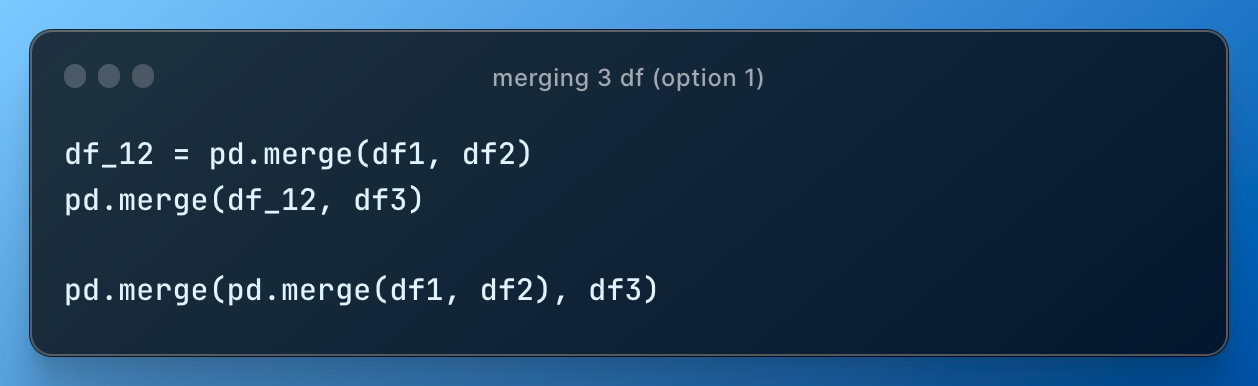
What if we need to merge 3 DataFrames?
Option 1 is using pd.merge() twice:
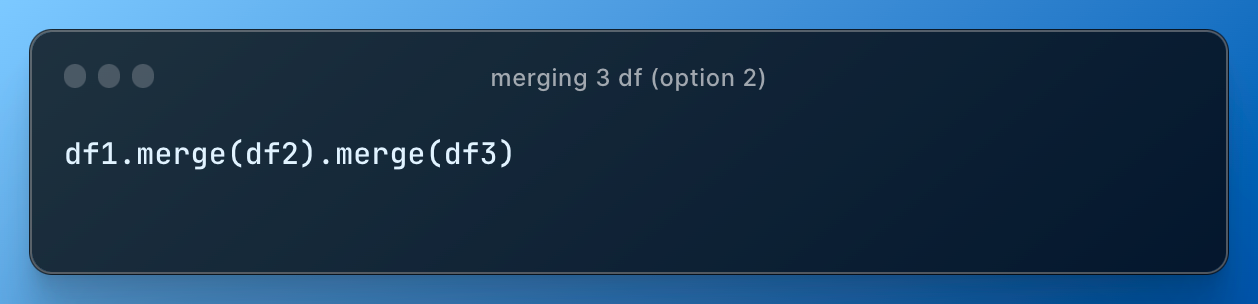
Option 2 that uses concept called chaining is
Option 2 is preferred way stylistically, because you can also add more operations such as dropping duplicates after merge (and many things in data are built conceptually in chains or pipelines):
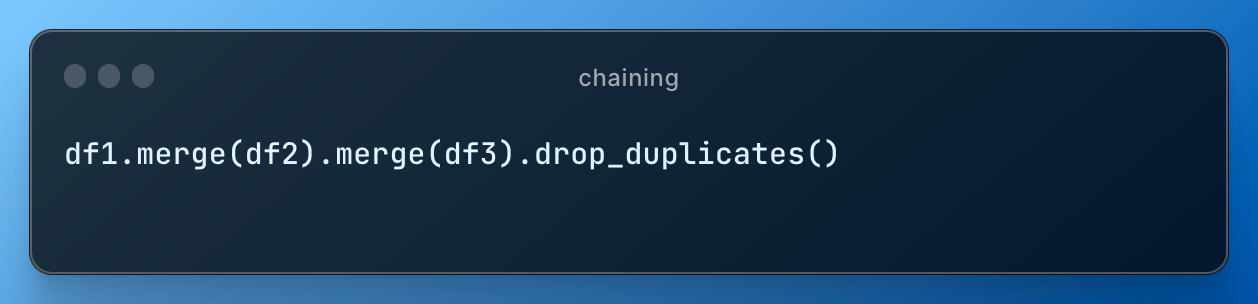
We got data pipelines.
We got ML pipelines (scikit-learn, Kubeflow).
Functional programming (e.g. PySpark) is indeed applying functions on result of previous functions (chaining).
In the new polars you use the same pattern of chaining: df.select(pl.col("sqft").sort() / 1000)
To sum up, beginners need to get used to pipeline thinking.
performance
In Python there are many ways to achieve the same thing. This applies to transformations of DataFrames and the way you choose to write transformation has implications, particularly on performance of an operation.
To demonstrate that I repeat this amazing tutorial using my dataset:
 Real Python
Real Python
Students are amazed how execution time drops from 1 s ± 61.6 ms (for-loop) to 763 µs ± 14.9 µs (pd.cut).
lesson #6: data visualisation
In this lesson I always tell a disclaimer that the lesson is not about beautiful charts that you need to build for data storytelling. Neither it is about building dashboards so that colleagues can use it – please, use commercial BI tools such as Power BI, Tableau or Looker.
This lesson is about how to do effective exploratory data analysis. I show how to use df.plot(), matplotlib, seaborn and my favorite plotly.express.
I prefer plotly because the code is cleaner, uses more intuitive names for chart types, there are much less of these methods, and overall requires much less code for customization, compared to matplotlib or seaborn.
However, seaborn has probably one of the most powerful charts that shows all you need to know about interactions of your columns and distributions in one place:

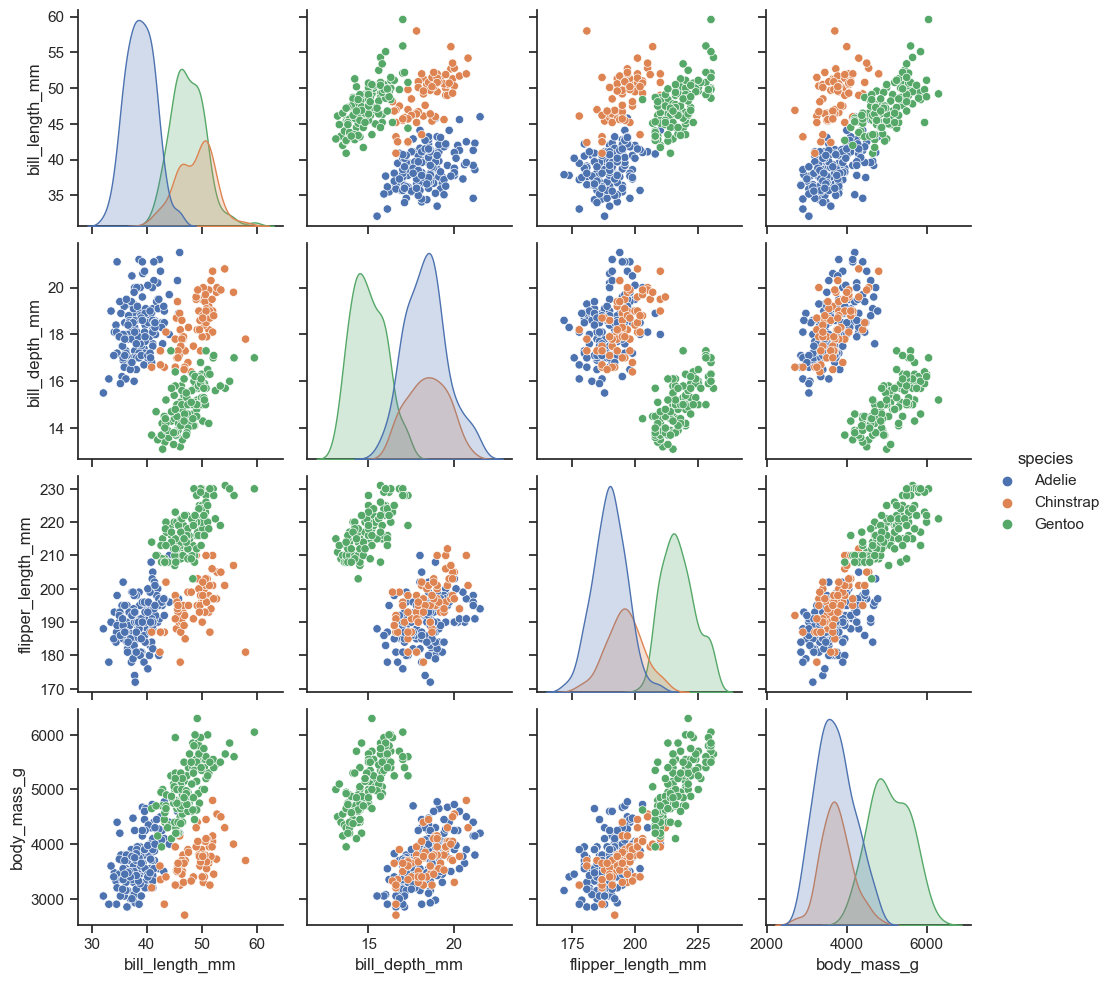
Similar implementation in plotly needs some extra work from the creators.
Finally, I show this little trick of coloring cells in correlation matrix that often is all you need:
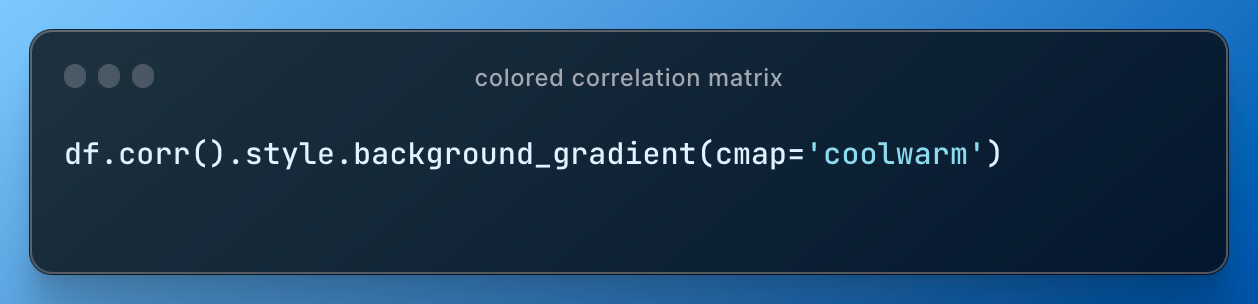
lesson #7: python beyond basics
Final lesson of Python.
I cover topics that are used in software engineering or much later in some ML-related code:
- generators
- used to process big data by reading data in batches
- recursion
- cool topic by itself, but not really used in data science
- caching
- decorators
- OOP (class, inheritance)
generator
Students already know that they can read the CSV file like this

But what if the CSV file is so big that we can't load it into our memory? This problem almost often happens when we deal with datasets for Deep Learning.
We use the concept of generators.
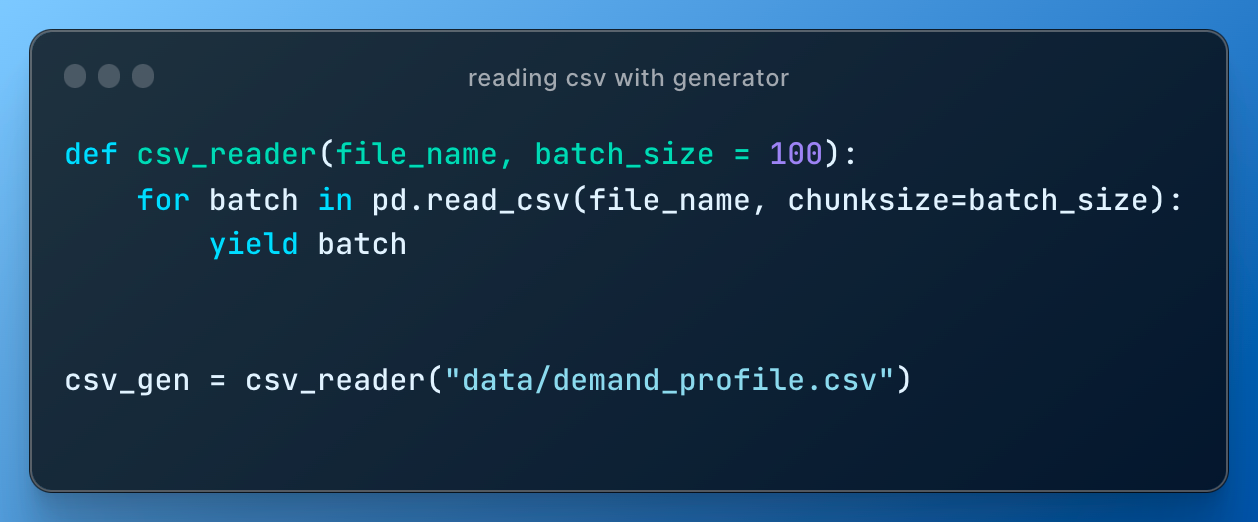
recursion
To explain recursion, caching and decorators I use Fibonacci generator problem, where we need to find Fibonacci number at order n.
Basic (inefficient) implementation with recursion is
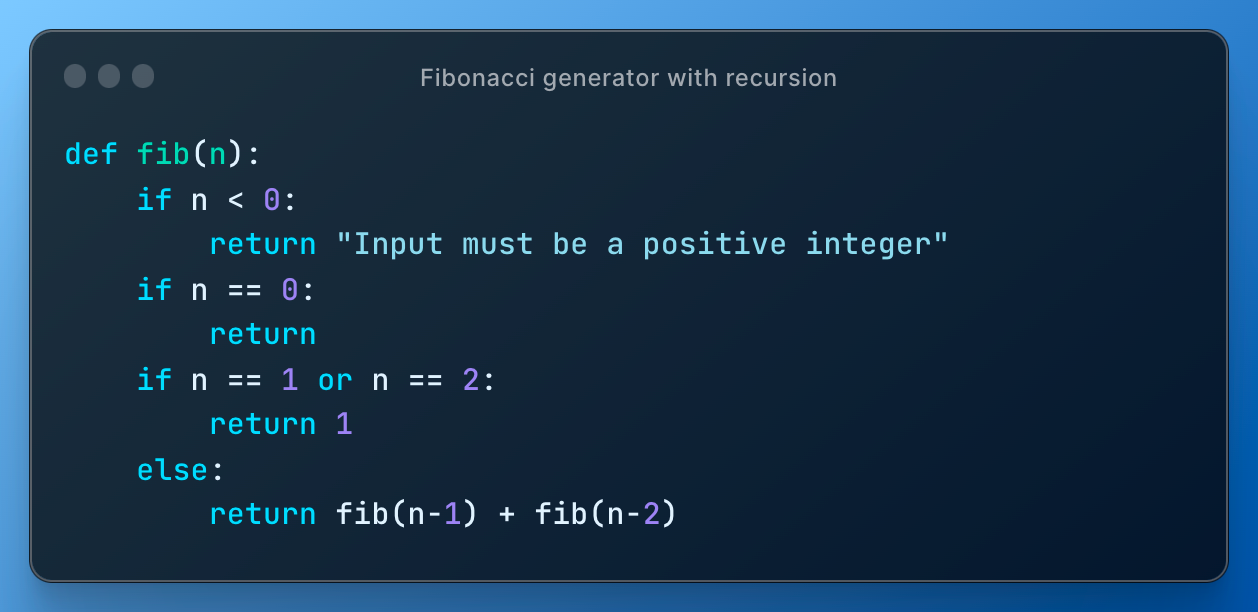
On my computer fib(40) takes ~30 seconds.
caching
In this implementation the inefficiency comes from running the same calculations many times and therefore memoization helps:
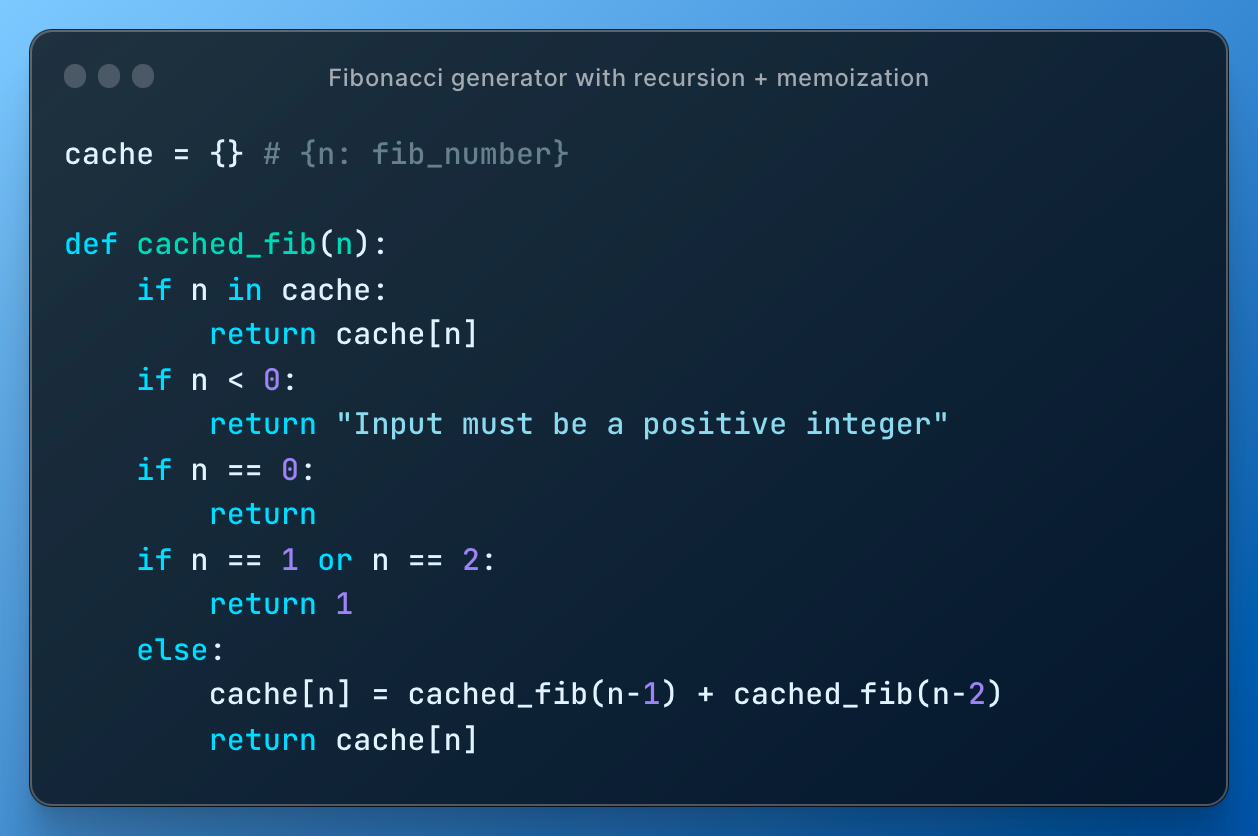
Now cached_fib(40) takes much less time.
decorator
I move to showing this implementation where I use decorator @cache:
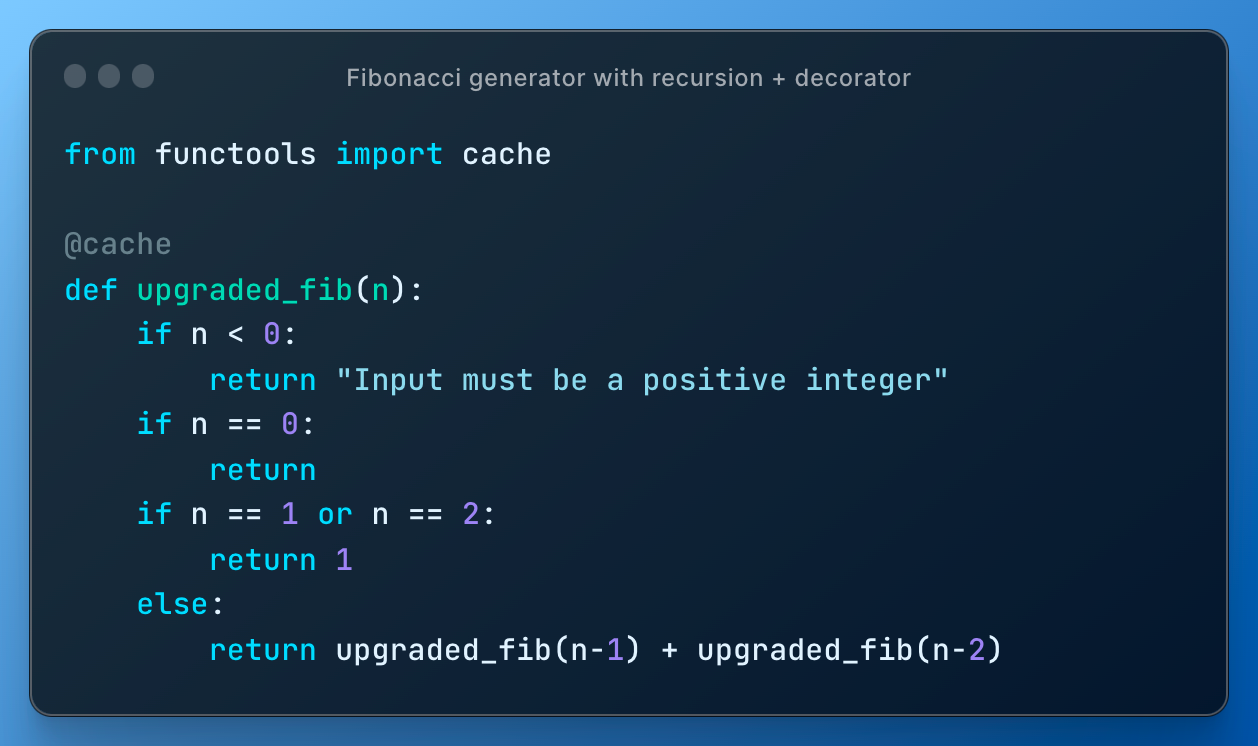
The function upgraded_fib(n) is exactly the same as inefficient fib(n) which means that decorator somehow upgraded it.
I re-implement @cache to show how the behavior (same input = same output) doesn't change but we still get extra functionality:
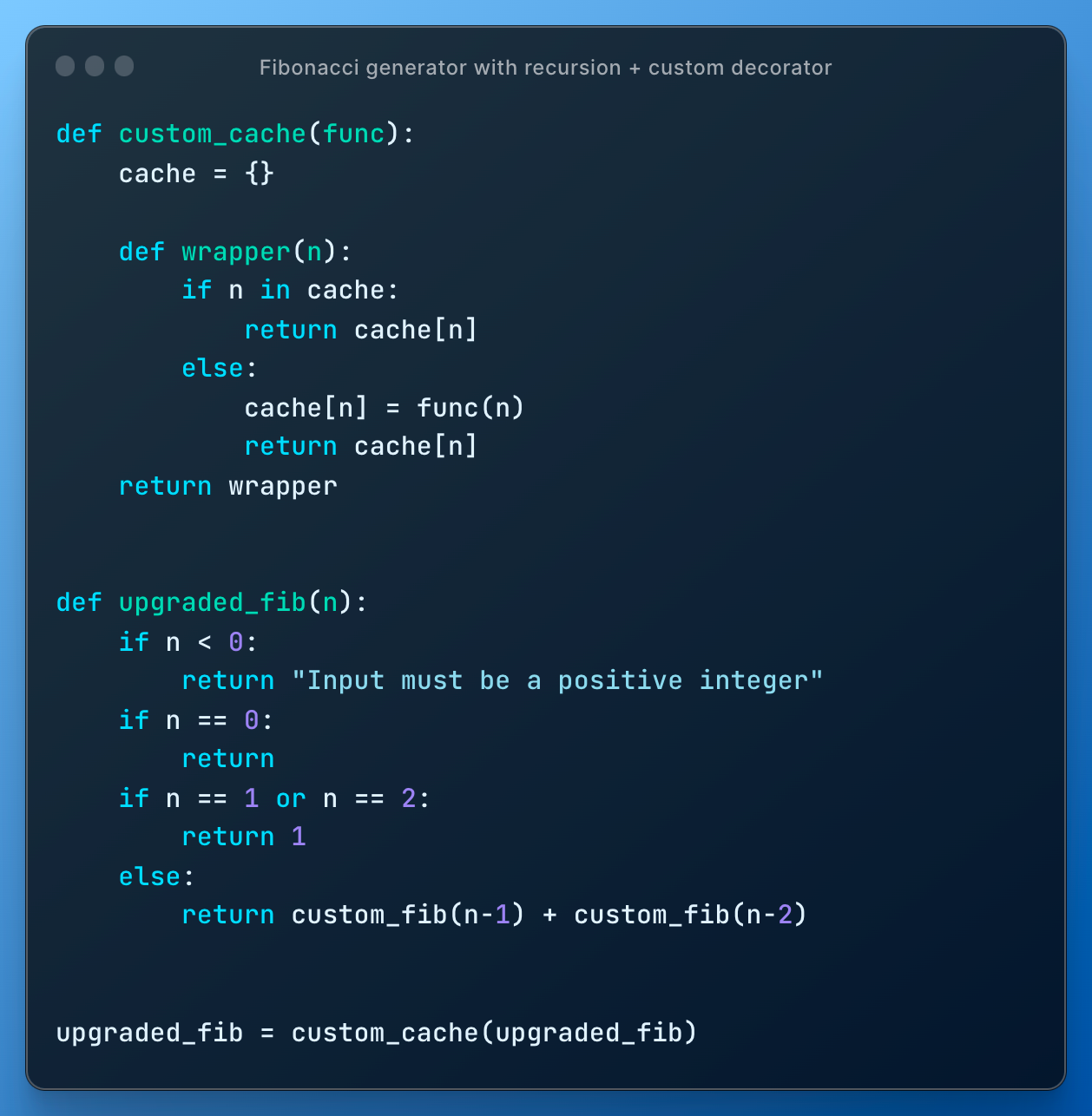
self-study
This is my Python 101 for Data Science.
It is extremely opinionated one and therefore I always emphasize that students need to do self-study.
I advise several resources (no particular order):
- exercism.org
- leetcode, hackerrank
- kaggle.com/learn
- DataCamp
- codecademy
- realpython
- freeCodeCamp
- ChatGPT / GitHub Copilot



