coding = writing text: approach it like an essay

Every person who writes code believes it is clean. What a fallacy!
I used to think the same until my colleague Manuel asked me to review his Pull Request (PR) for a project we were working on. As I reviewed his code, I realized that his code is so much cleaner than mine.
What made his code cleaner? Uff, I wouldn't be able to tell, but it felt better. It is like reading your own university essay and then reading one by Paul Graham or Malcom Gladwell - you just know there's a difference.
At first, I thought it was just my lack of experience with JavaScript/TypeScript (as a data scientist I mostly wrote Python before). But in reality, it was just me not paying enough attention to and not recognizing all patterns of clean code.
Manuel recommended me a book by Robert C. Martin and I bought it immediately. The book is called The Clean Code: A Handbook of Agile Software Craftsmanship. It's an extensive and detailed book that you should not read as a novel from start to finish within a day or two. Instead, it serves as a handbook - read a chapter, reflect on it, and ideally apply it in your work. While the code examples are in Java, most of the lessons are universal to other languages.
In this blog post I won't be summarizing or paraphrasing the entire book. First, honestly I don't think I internalized the entire wisdom written there to be able to share it effectively. Second, I encourage everyone to read the book and draw their own conclusions from original source. This advice applies to any topic - always go to the original source. Finally, the book has so many valuable insights that a single blog post can't capture them all.
Instead, in this blog, I'll share the first key takeaway I gained after reading and applying some of its principles.
Let me give one example of code and how to rewrite it if you think about the code as an essay.
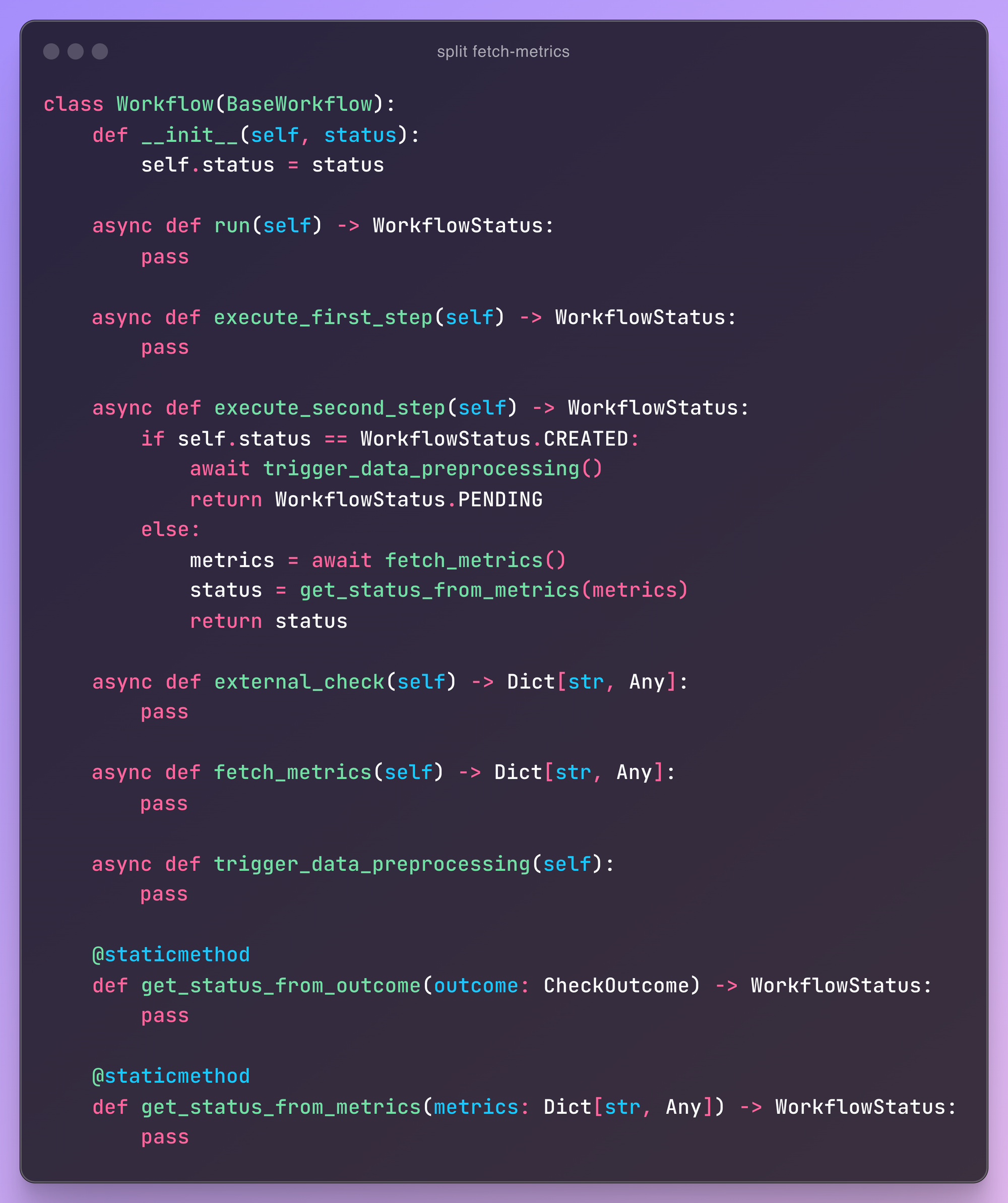
code example
Suppose that we have a pipeline or a workflow that executes a set of checks. First it runs external_check . If this external check returns APPROVED, then it proceeds with the second step where the status is determined based on metrics.
Here is some dummy implementation of this workflow:
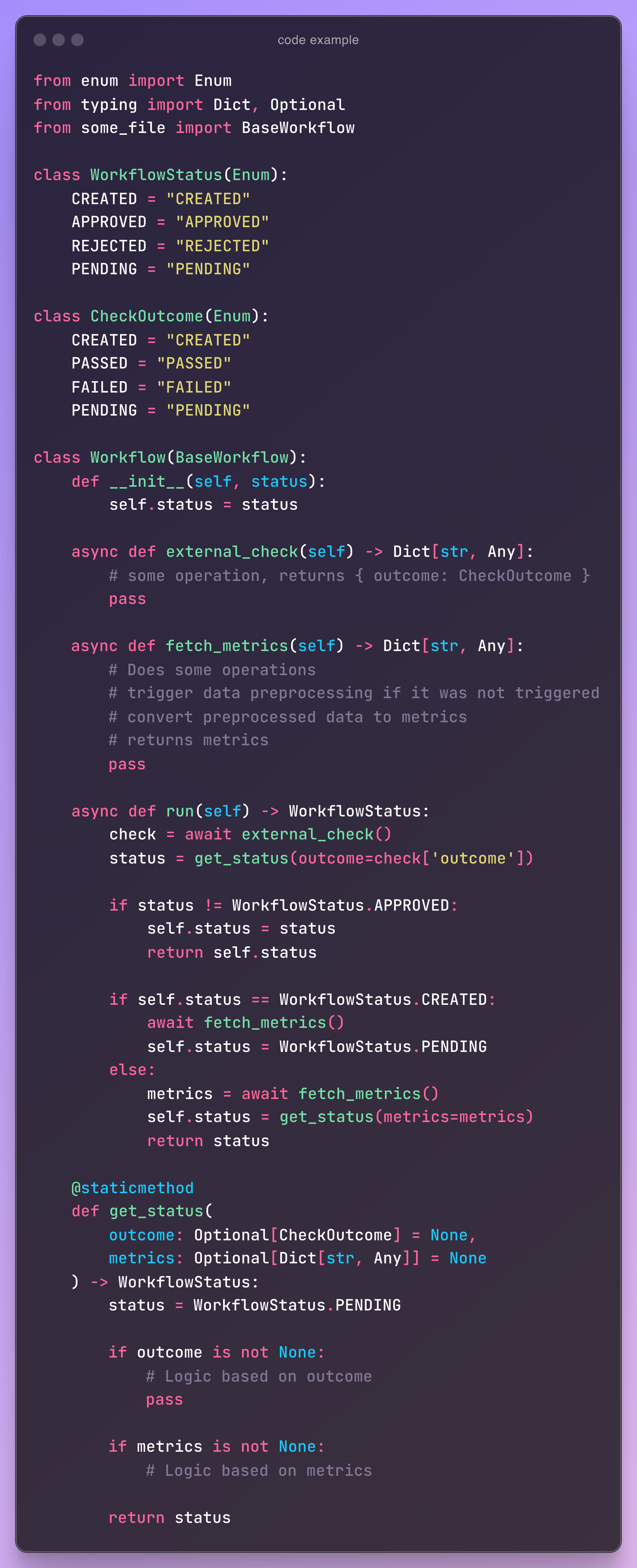
improvement #1: write from top to bottom
The main method in this class is .run() which is how this workflow will be used in other codebase. Imagine you see somewhere in the codebase workflow.run() and you want to know what it does.
You scroll down to the middle of the file to find .run() implementation. It references three other methods: .external_check() , fetch_metrics() and get_status. So, you scroll up a bit to check implementation of the first two methods. Where is get_status ? Ahh you scroll down again, this time to the bottom of the file, to find its implementation.
Quite a lot of scrolling to follow the code. Imagine reading an essay where the introduction is halfway down the page, the main arguments are at start, and the resolution is in the bottom. We can structure our code better than that.
How about reorganizing the code so that as you follow it, you only need to scroll down? This way, everything flows naturally, just like reading a well-structured document.
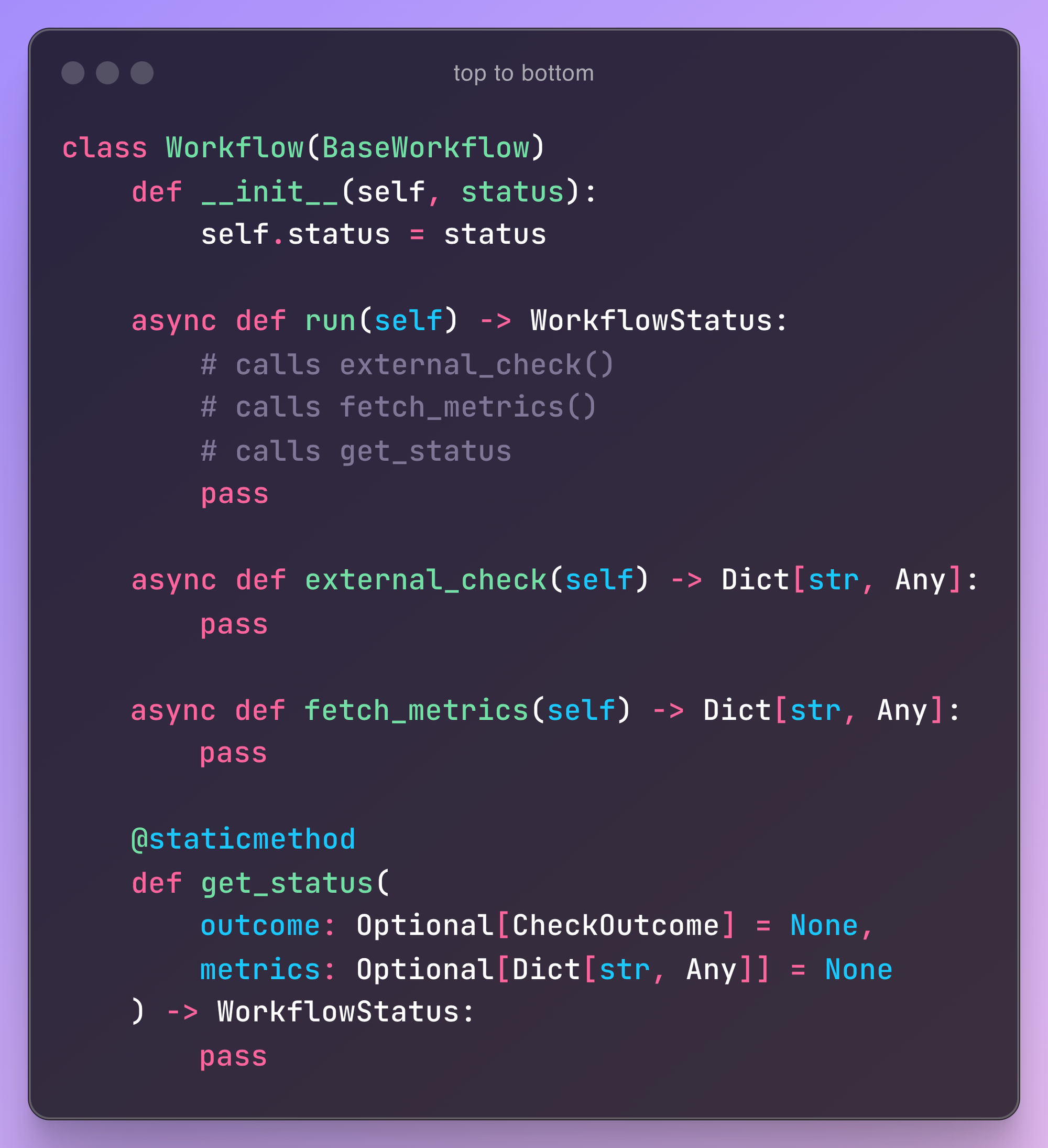
improvement #2: group into chapters
The code inside .run() handles several tasks at varying levels of abstraction: it calls an external check, fetches metrics, and derives the status from both. However, at its core, it’s a two-step process. First, it performs an external_check (Step 1), and only if the first step is APPROVED does it proceed with the rest of the code (Step 2). If this were a book, these would be two distinct chapters: one for each step.
So, let's break .run() into two separate methods: execute_first_step() and execute_second_step(). This division allows us to enhance each step with more complex logic without altering the original .run() implementation.
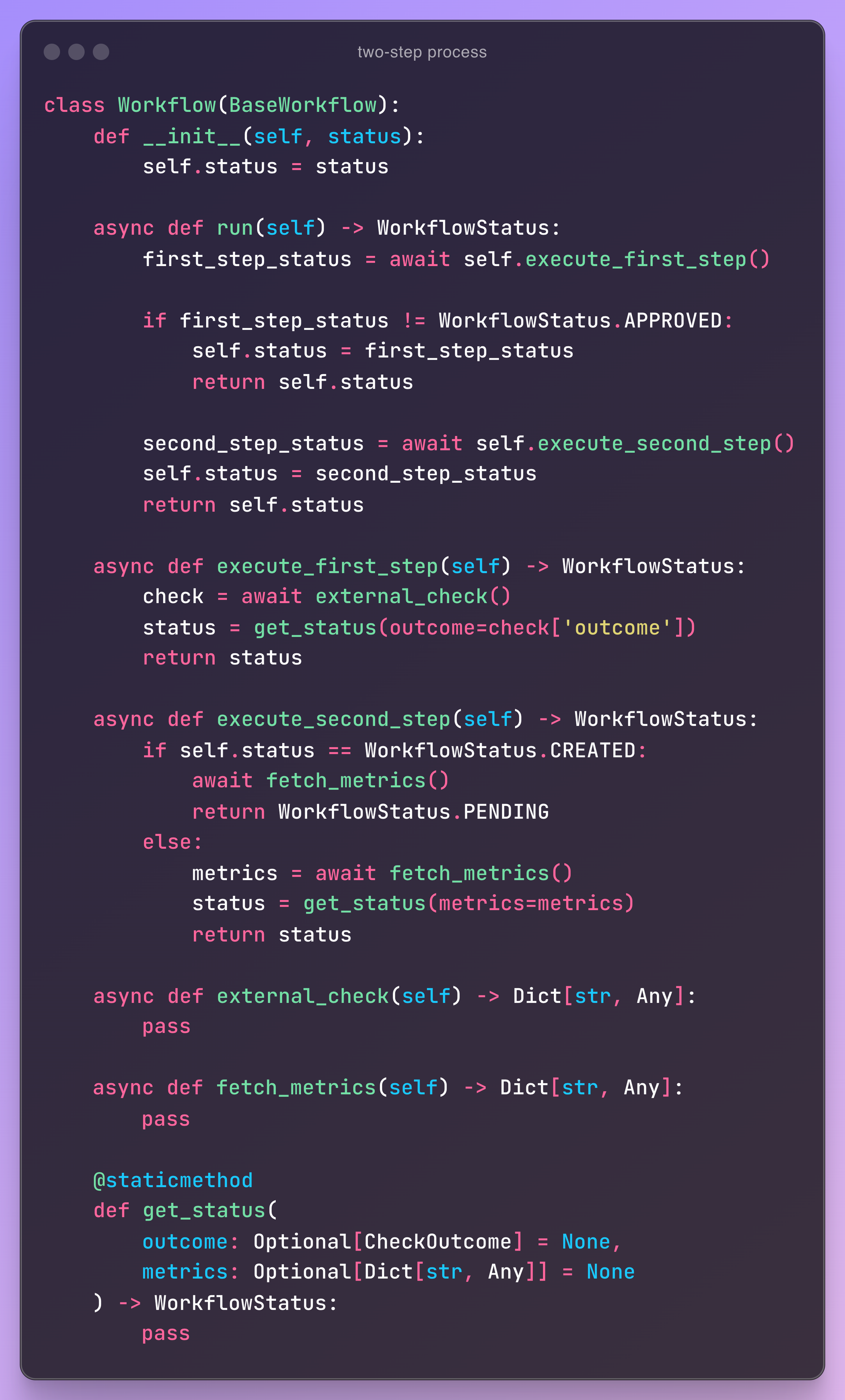
improvement #3: have intentional naming
Now let's take a closer look at the other methods: get_status and fetch_metrics.
The get_status method's name suggests it returns a status , which is clear and straightforward. However, we notice that get_status() takes in two unrelated arguments: outcome and metrics. To understand what this method does, how it uses each argument, and what arguments it actually accepts, you'll need to dive into its implementation—especially if you plan to use it elsewhere.
To make the code more intuitive, let's improve the naming and split it into two methods: get_status_from_outcome and get_status_from_metrics. This not only simplifies the functions and ensures each does only one thing, but also makes it clear what each method accepts and returns, just from their names:
get_status_from_outcome: accepts outcome and returns statusget_status_from_metrics: accepts metrics and returns status
Otherwise, instead of creating get_status_from_outcome, we could also consider get_status_from_check which would allow us to pass the entire check variable directly, rather than just check['outcome'].
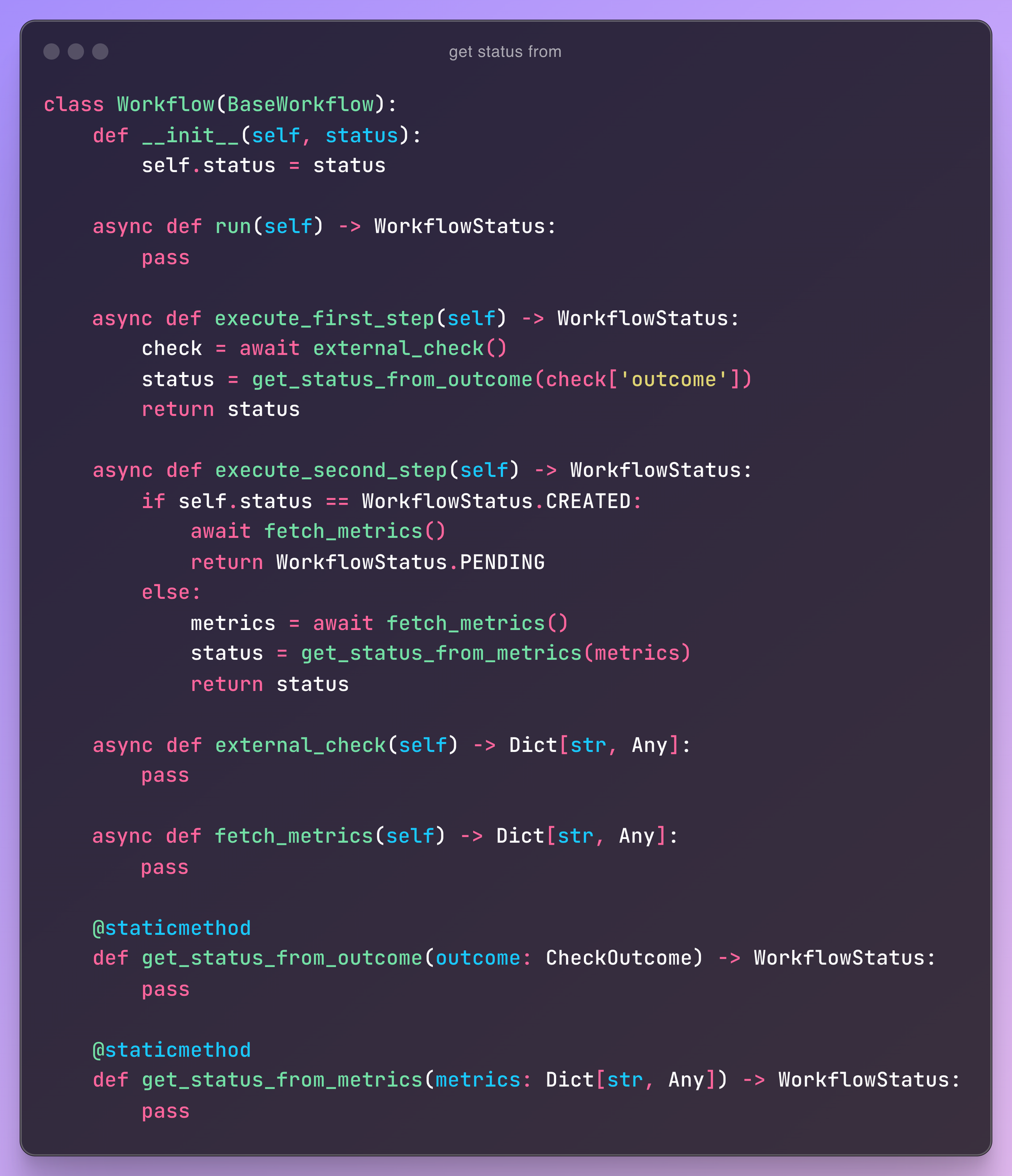
Now let's take a closer look at execute_second_step().
This method uses fetch_metrics. From the name, you'd expect it to simply fetch metrics from somewhere. When the current status isn't CREATED, the method is used exactly that way: it fetches metrics, stores them in a metrics variable, and then the status is determined from these metrics.
However, when the status is CREATED, the function is called without saving its output. This suggests that fetch_metrics is doing something more than just fetching metrics, contrary to what the name implies.
To address this confusion, we need to dive into the implementation of fetch_metrics. Upon inspection, we find that it actually performs two tasks:
- It triggers a data pre-processing job if it hasn't been triggered already.
- It fetches the pre-processed data and converts it into metrics.
The solution is to refactor fetch_metrics so that the data pre-processing logic is separated into its own function, e.g. trigger_data_preprocessing(). This will make the code more understandable and prevent any misconceptions about what fetch_metrics is doing.
Ultimately, the names of functions and variables should reflect their purpose and intention clearly. By choosing meaningful names, you're essentially translating your plan—"first, I will trigger data processing, then I will fetch metrics, and finally, I will derive the status from these metrics"—into the code itself. The specific details, such as how processing or fetching is implemented, become secondary and abstracted away. The core plan remains clear and easy to follow, ensuring that anyone reading the code understands the overall structure and flow at a glance, much like skimming a book by chapters and then diving into each chapter by sections.
final code example
So, with few simple improvements, we got the following code:
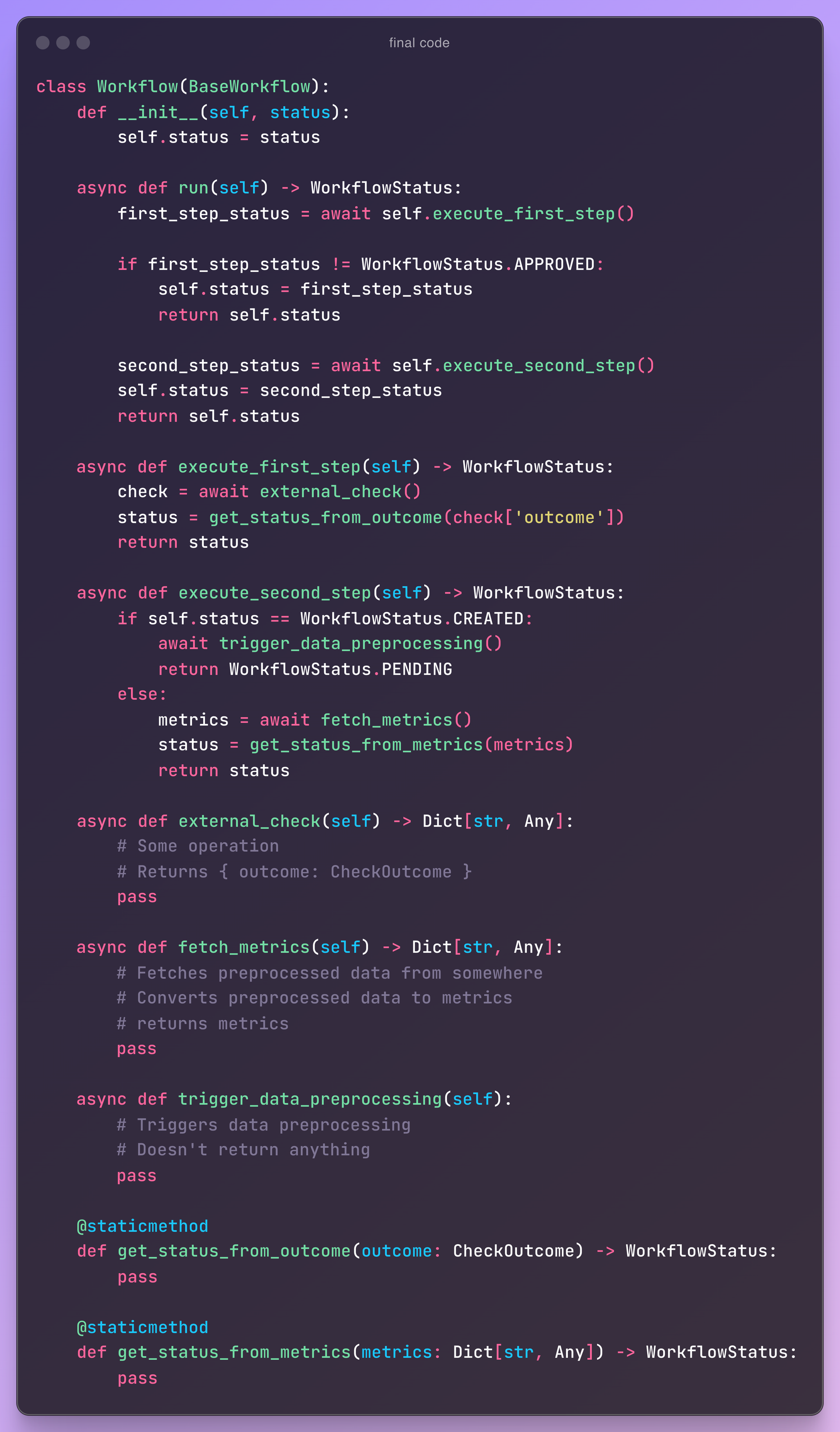
Does it look better? What else can be improved?



